

Abstract Data Type of ADT is a class or type for objects with behavior that is defined by a set of operations and a set of values. Considering the definition of ADT, it only states the operations which are to be performed but not how they will be implemented. It fails to specify how the data will be arranged in memory and the algorithms that will be used for implementing those operations. The reason why the data is called ‘abstract’ is that it provides an implementation-independent view. The entire process of offering only the essentials and keeping away the details is known as abstraction.
In this blog, we have tried to explain different aspects of abstract data types – it’s types, advantages, typical operations, implementation, etc.
Abstract Data Types
The user of an abstract data type doesn’t necessarily know the ways in which the data is implemented. For example, we have been using Primitive data types like int, char, float, etc., only having the knowledge that these are the data types that can operate and be performed on, without any prior idea of the ways of its implementation.
In simpler terms, users just need to know the work/job a data type can do and not how it will get implemented. You can assume ADT as a black box that provides cover to the inner structure and design of a particular data type.
Now, let’s talk about different ADTs:
- List ADT
- Stack ADT
- Queue ADT
List ADT
In a list ADT, the data is usually stored in a key sequence (in a list) which has a head structure that contains pointers, count, address of compare function required to compare the data in the list.
See the figure below to get a rough idea of list ADT:
The data node consists of the pointer to a data structure and a self-referential pointer, pointing to the next node in the list.
Example:
//List ADT Type Definitions
typedef struct node
{
void *DataPtr;
struct node *link;
} Node;
typedef struct
{
int count;
Node *pos;
Node *head;
Node *rear;
int (*compare) (void *argument1, void *argument2)
} LIST;
Functions of List ADT
A list consists of elements of the same type organized in sequential order and can perform the following operations:
- insert(): Operation used to insert an element at any position of the list.
- get(): To return an element from the list at any position.
- replace(): To replace an element at any position by another element.
- remove(): For removing the first occurrence of any element from a non-empty list.
- removeAt(): For removing the element at a specified location from a non-empty list.
- size(): It is to return the number of elements in the list.
- isFull(): To return ‘true’ in case the list is full, or else return ‘false’.
- isEmpty(): To return ‘true’, if the list is empty, otherwise return ‘false’.
Stack ADT
In case of Stack ADT, it’s implementation instead of data is stored in each node, the pointer to data is stored. The program allocates memory for the address and data, which is passed to the stack ADT.
The data nodes and the head node are included in the ADT. The calling function can only see the pointer to the stack. Talking about the stack head structure, it consists of a pointer to top and a count of the number of entries presently in the stack
Example:
//Stack ADT Type Definitions
typedef struct node
{
void *DataPtr;
struct node *link;
} StackNode;
typedef struct
{
int count;
StackNode *top;
} STACK;
Functions of Stack
A Stack contains elements of a similar type organized in sequential order. All operations take place at a single end – at the top of the stack and it can perform the following operations:
- pop(): To remove and return the element at the top of the stack, only when it is not empty.
- push(): In order to insert an element at one end of the stack (at the top end).
- peek(): For returning the element at the top of the stack without removing it, only when it is not empty.
- size(): To return the number of elements in the stack.
- isFull(): To return ‘true’, if the stack is full, or else return ‘false’.
- isEmpty(): To return ‘true’, if the stack is empty, or else return ‘false’.
Queue ADT
The third is queue ADT (abstract data type) that follows the basic design of the stack ADT.
Each node of queue ADT consists of a void pointer to the data and the link pointer to the next element in the queue. The responsibility of the program is allocating memory to store the data.
//Queue ADT Type Definitions
typedef struct node
{
void *DataPtr;
struct node *next;
} QueueNode;
typedef struct
{
QueueNode *front;
QueueNode *rear;
int count;
} QUEUE;
Functions of Queue ADT
A Queue consists of elements of the same type organized in sequential order. The operations here take place at both the ends. Insertion is done at one end and deletion is done at the front. Here are the operations that can be performed with this abstract data type:
· peek(): To return the element of the queue without removing it, only when the queue is not empty.
· dequeue(): To remove and return the initial element of the queue, only when it is not empty.
· enqueue(): In order to insert an element at the end of the queue.
· isFull(): For returning ‘true’ when the queue is full, or else return ‘false’.
· isEmpty: To return ‘true’ when the queue is empty, or else return ‘false’.
· size(): To return the number of elements in the queue.
From the above definitions of the different ADTs, we can understand that these abstract data types do not specify the way of their way of implementation by any chance and the methods in which the operations will be performed. There can be various methods for implementing ADT.
For example, List ADT can be implemented using arrays, of by singly linked or doubly linked list. In the same way, stack ADT and Queue ADTs can be implemented using linked lists or arrays.
Typical operations for ADTs
Here are some operations that are mostly specified for abstract data types (ADTs):
- Hash(S): It is an operation that computed some standard hash function from the instance’s state.
- Compare(S, t): It tests if the state of two instances is equivalent in any possible sense.
- Print(S) or shows(S): It produces a representation of the instance’s state easy-to-read by humans.
In an imperative-style ADT definition, you might also find operations, such as:
- copy(S, t): It is an operation that puts instance ‘S’ in a state equivalent to ‘t’.
- create(): It yields a new instance of the ADT.
- clone(t): The operation performs s ← create(), copy(S, t) and return ‘S’.
- initialize(S): This one prepares a newly formed instance ‘S’ for other operations or resets it to an ‘initial state’.
- free(S) or destroy(S): it reclaims the memory and resources utilized by ‘S’.
The ‘free’ operation of ADT is not usually meaningful or relevant, as abstract data types are theoretical entities that do not ‘use memory’. But, it may be crucial when you need to analyze the storage used by an algorithm that utilizes the ADT. In such cases, you will need additional axioms which state how much memory every ADT instance utilizes, as a function of its respective state and the memory returned to the pool by ‘free’.
Implementation of ADTs
To implement an ADT is to provide one function or procedure for each abstract operation. By now, you know that ADT instances are represented by some concrete data structures. This data structure is manipulated by those functions or procedures based on the ADT’s specifications.
Generally, there are different methods to implement the same abstract data type, using different concrete data structures. Consider this example – an abstract stack can be implemented by an array or a linked list.
In order to prevent clients from depending on the implementation, an ADT is usually packaged in one or more modules as an ‘opaque data type’, whose interface consists only of the signature (number and types of the parameters and results) of the operations. The implementation of the module, such as the concrete data structure used and the bodies of the procedures can be hidden from most clients of the module. In this way, it becomes possible to alter the implementation without affecting the clients. In case the implementation is exposed, it is called ‘transparent data type’.
While implementing an abstract data type, each state of each instance is mostly represented by a handle of some sort. Modern object-oriented languages, such as Java and C++, support a form of ADTs. When a class is used as a data type, it is an abstract type referring to a hidden representation. In this model, an ADT is implemented as a class and each instance of the abstract data type is an object of that class.
The interface of the module generally declares the constructors as ordinary procedures and as ‘methods’ for other ADT operations. But, such an approach doesn’t easily include multiple representational variants found in the abstract data type (ADT). It can also undermine the extensibility of object-oriented programs. In an object-oriented program using interfaces as types, types don’t refer to representations but behaviors.
Example of implementation of the abstract stack
Consider this example of an implementation of the Stack ADT in the C programming language.
Imperative-style interface
typedef struct stack_Rep stack_Rep; // type: stack instance representation (opaque record)typedef stack_Rep* stack_T; // type: handle to a stack instance (opaque pointer)typedef void* stack_Item; // type: value stored in stack instance (arbitrary address) stack_T stack_create(void); // creates a new empty stack instancevoid stack_push(stack_T s, stack_Item x); // adds an item at the top of the stackstack_Item stack_pop(stack_T s); // removes the top item from the stack and returns itbool stack_empty(stack_T s); // checks whether stack is empty
An idea how the interface can be used:
#include <stack.h> // includes the stack interface stack_T s = stack_create(); // creates a new empty stack instanceint x = 17;stack_push(s, &x); // adds the address of x at the top of the stackvoid* y = stack_pop(s); // removes the address of x from the stack and returns itif (stack_empty(s)) { } // does something if stack is empty
This interface can be implemented in several ways. It may be arbitrarily inefficient as the definition of ADT doesn’t determine the amount of space the stack may use, nor how long each operation may take. Moreover, it doesn’t even specify whether the stack state ‘S’ exists after a call ‘x ← pop(s)’.
The formal definition should specify that the space is proportional to the total number of items pushed and not popped yet. It should also specify that each of the operations stated above must finish within a constant amount of time, independently of that number.
In order to match with these additional specifications, the implementation could utilize an array or a linked list together with two integers.
Functional-style interface
In functional-style ADT, the definitions are more appropriate for the functional programming languages. But, one can provide a functional-style interface in an imperative language such as C.
Consider the following example:
typedef struct stack_Rep stack_Rep; // type: stack state representation (opaque record)typedef stack_Rep* stack_T; // type: handle to a stack state (opaque pointer)typedef void* stack_Item; // type: value of a stack state (arbitrary address) stack_T stack_empty(void); // returns the empty stack statestack_T stack_push(stack_T s, stack_Item x); // adds an item at the top of the stack state and returns the resulting stack statestack_T stack_pop(stack_T s); // removes the top item from the stack state and returns the resulting stack statestack_Item stack_top(stack_T s); // returns the top item of the stack state
Advantages of Abstract Data Type
Now that you know about the different types, operations and implementation of ADT, let’s throw some light on its advantages.
Encapsulation
Abstraction renders a promise that any implementation of the abstract data type has specific abilities and properties. It is all that is to be known in order to make use of an ADT object. You do not need to have any technical knowledge of the ways to implement ADTs for using them. With the help of encapsulation, even a complex implementation can be encapsulated into a simple interface when used.
Localization of change
Codes that utilizes an ADT object will not require any edit, in case the implementation of the abstract data type is changed. It is important that any change to the implementation must comply with the interface. And, the code using an abstract data type object can only refer to abilities and properties specified in its interface. As such, the changes can be made to the ADT implementation without any need to change the code where the abstract data type is used.
Flexibility
Different implementations of the abstract data type, with the same abilities and properties, are equivalent and can be used interchangeably in code that uses the abstract data type. In this way, it offers flexibility while using ADT objects in various conditions.
For example, different ADT implementations may be more effective in different situations. It is possible to use each implementation in a situation where they are preferable. This increases overall efficiency.
How to create ADTs in C
Many software developers consider object-oriented programming like Java and Python as a great tool for building applications and software. And, software engineers using the procedural C language (programming language) miss the several modern features of programming languages. As we know, ADTs or abstract data types are the data types that keep the implementation details hidden from the users.
We can develop ADTs using the conventional C programming language. Read the below-mentioned steps to know how:
#1: Define the ADT
The abstract data type in C is defined as a pointer to a data structure. There’s a header file that consists of the ADT declaration without any hidden details, leaving it for the implementer to completely declare the abstract data type in the source module.
Example of ADTs:
Some of the examples of ADTs are a StackPtr_t, QueuePtr_t, NodePtr_t, etc.
Below is an example of how a developer might declare an abstract data type:
Typedef struct StackStruct_t * StackPtr_t;
It will take the declaration in the stack.h file. This enables the user of the module to make use of StackPtr_t. It is a pointer to StackStruct_t. From the users’ perspective, the details of StackStruct_t’s members are totally hidden. Any kind of interaction with StackPtr_t must be done with predefined operations.
#2: Define the operations to be performed on the data
To decide what operations you can perform on an abstract data type is based on the purpose of the ADT. Suppose, an ADT for a stack can include operations such as pushing data, initialization, destroying the stack, popping data, checking if the stack is empty, checking if the stack is full and others.
You must keep in mind that there’s a difference between the way you use an abstract data type and the way you generally manipulate data. Being a developer, you can create an interface with an ADT where the data is modified indirectly behind the scenes. On the contrary, defining the data and writing the data are ways to directly manipulate the data.
#3: Fill in the specification of the interface
The specification of the interface is the function prototype for every public operation that you can perform on the abstract data type. Remember to locate the interface specification in the header file of the ADT. Refer to the above stack example again, you will see the interface specifications looking like the below image:
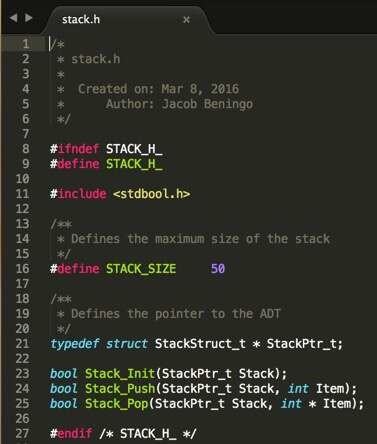
#4: Create the ADT implementation
The implementation of the ADT can change from one application to another; it can even change during project development. This one is among the nicest aspects of using an abstract data type – the implementation details are stored in the source module and remain ‘hidden’ from the view of the higher-level application developer. Thus, using an ADT offers a developer with a high degree of flexibility.
Here’s an example of what areas of the Stack ADT implementation may look:
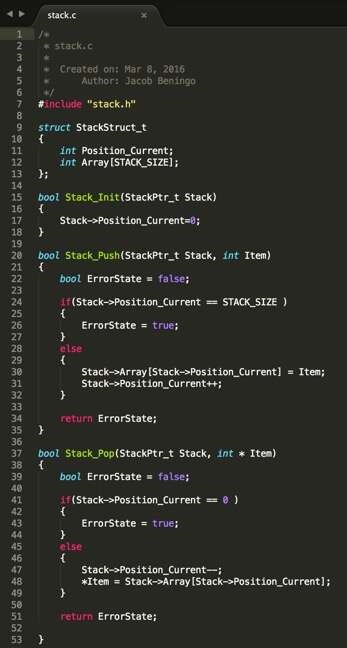
#5: Test the ADT
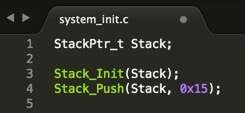
The final step is when you have specified and implemented an Abstract Data Type (ADT) and move to put the ADT to test. It is done by writing application code. The application code should be a declaration of the ADT and then it manipulates the contents of the data with the help of the interface specifications.
Consider the example of initializing the ADT and interacting with the data included:
In a Nutshell
ADT or Abstract Data Types allows you to know what operation can be performed but not how those operations will be implemented. We hope, you are now aware of the different types of ADTs, it’s operations and implementation.
If you are an aspiring developer, you can try creating an ADY referring to the above steps. The purpose of an abstract data type is to keep the implementation details hidden, thus enhancing software maintenance, portability and reuse. Developers are seen using ADTs to find that they have the ability to adapt to altering requirements and save time by not involving in code searching for data references.